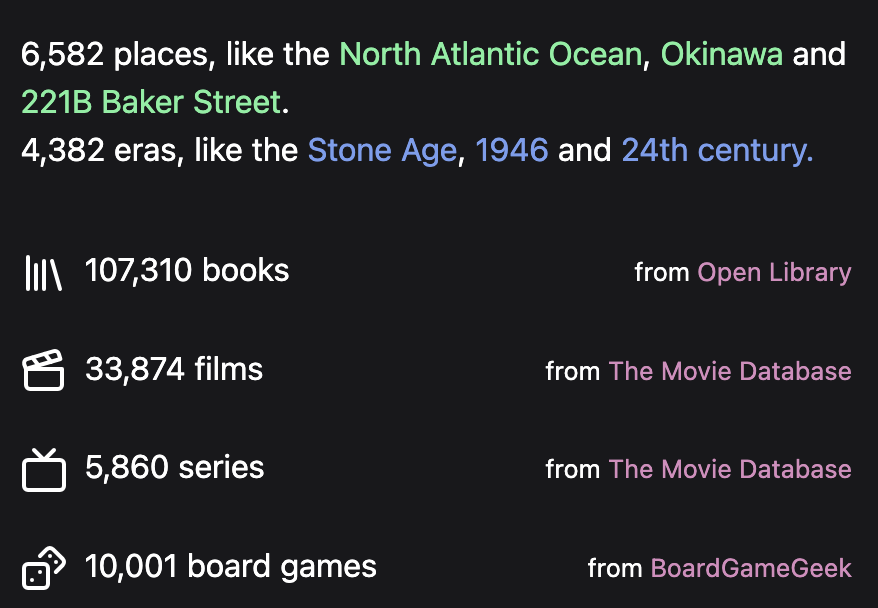
Whenever is my latest passion project: it’s a mappy web database of films, series, books and board games organised around when and where they are set: Paris in the 19th century, Canada in the 1970s, China in the Han Dynasty. You can play with it at whenever.world. It currently has:
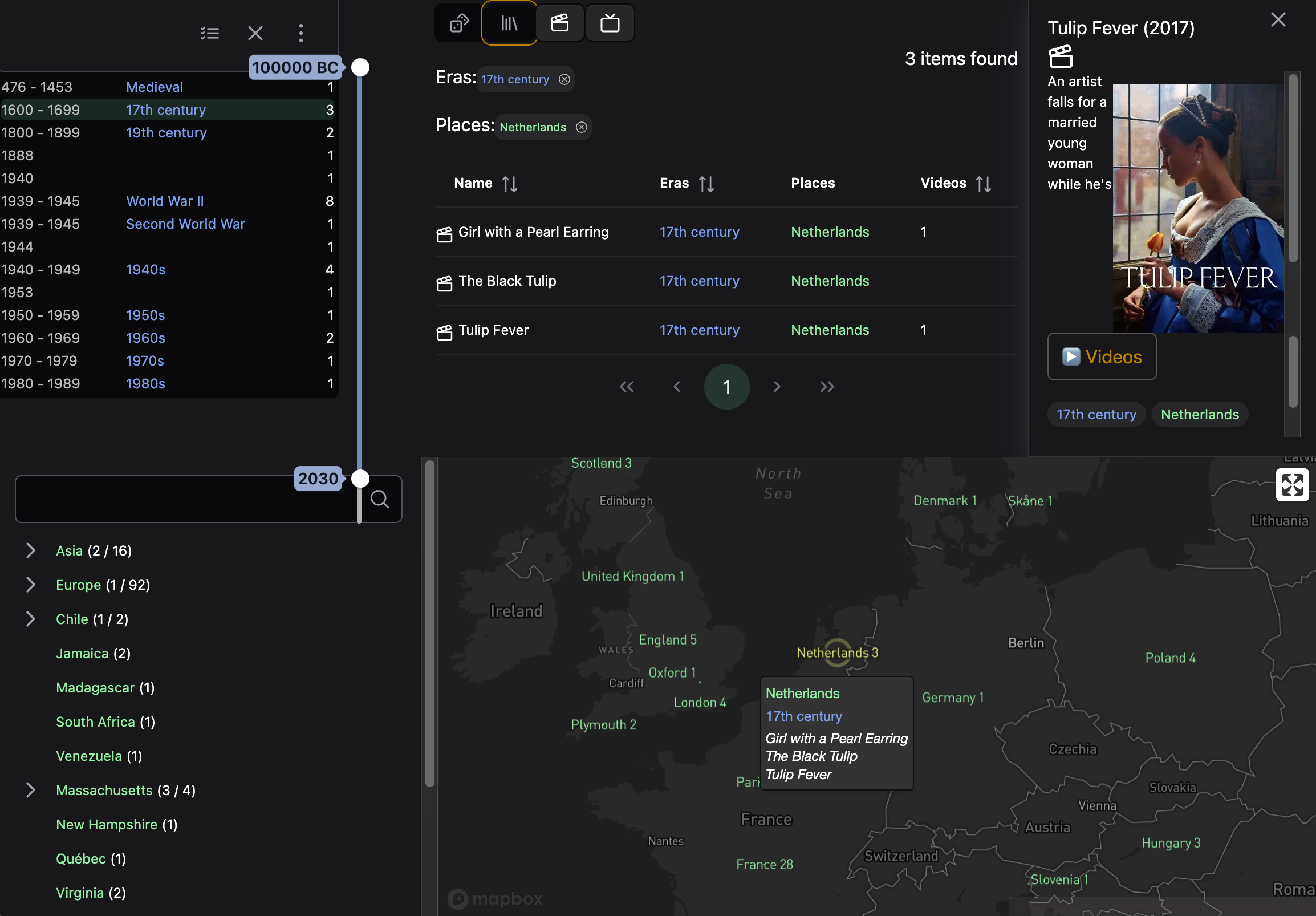
I had the idea a few years ago after watching Tulip Fever, set in the 17th century in the Netherlands. I’d never seen or read anything about that time and place. What others was I missing out on? Certain settings recur frequently: wartime Britain, New York in the 1960s, 18th century France. But what else is out there?
At its heart, Whenever’s database has a very simple schema. A place has a point location, a name, and possibly a parent (Paris belongs to France). An era has a name, a start year and an year year. An item has a type (book, film, series, board game) and a few general details like publication date and description. And a setting ties an item to an era or a place.
But there is a ton of complexity and messy data processing to make it all work. Where do you get a list of eras from? And locations? How do you match them? How do you know which of many cities named “St Peter” or “Derby” or even “Athens” a description is referring to? Fortunately, while the questions are hard, they’re also interesting and fun to work on.
Books
OpenLibrary is a massive database of information about books, both crowd-sourced and harvested from libraries, run by the Internet Archive. There’s no API, but comprehensive data dumps of 60 million editions of 40 million different books. One of the hardest challenges was simply identifying fiction books: I want books set in Mogadishu, not books about Mogadishu. This is more involved than it sounds: categories like “fiction” or “literature” often contain books about literature.
With much trial and error I ended up with this Regular Expression for Dewey Decimal codes:
The OpenLibrary schema helpfully has “place” and “time” tags, but of course they are free-text, and there is no guidance about what they mean. There’s some idiosyncratic disambiguation (“Seattle (Wash.)”), multiple languages (“Angleterre”), and all kinds of weirdness. And I still don’t know quite what to do with tags like “to 1788”.
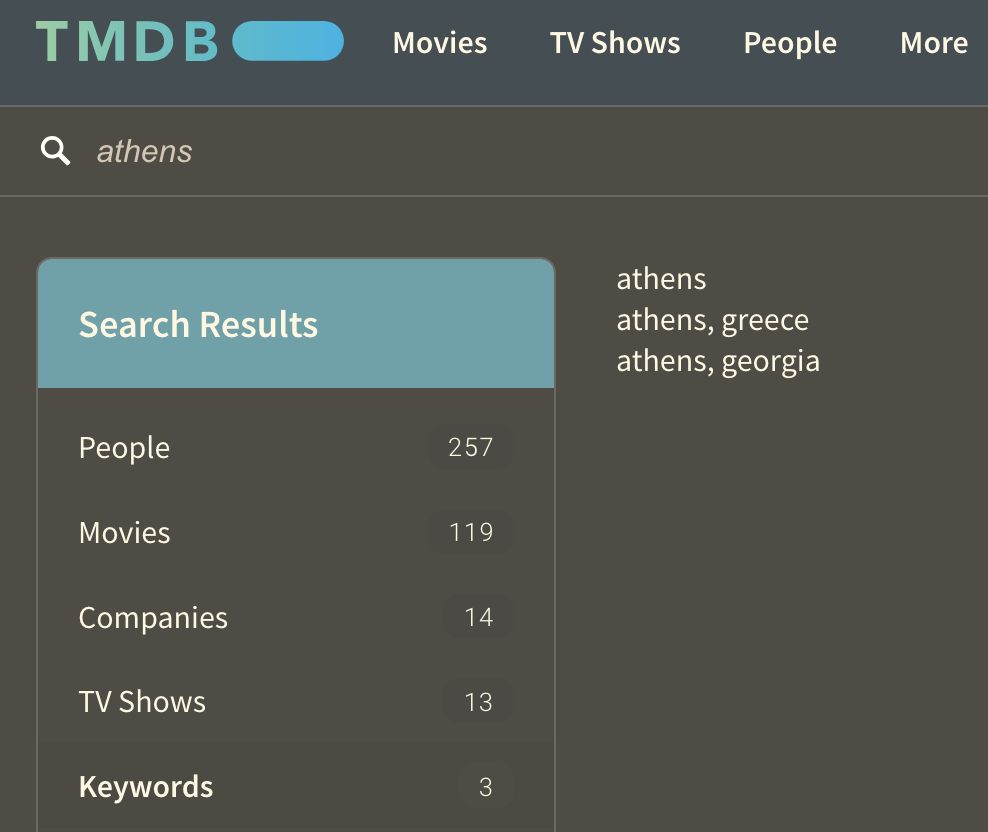
-sourced alternative to IMDB, and has been around a long time. It has a great API with no real usage restrictions, but no data dumps. It has a less specific system of keywords, where “georgia” can mean the US state, “georgia europe” the country, and “georgian” the reign of King George.
So instead of attempting to download the whole thing and processing it, my scripts first try to find a keyword for each place and era; Paris corresponds to keyword 355249. There’s some logic to accept “Athens, Greece” as a possible keyword name, but reject “Athens, Georgia”.
Then for each keyword, we fetch all the connected movies. And then there’s a second pass to collect additional metadata for each film, particularly the list of trailers and other videos available about the film. This is an incredible bonus, letting you immediately jump into at least a glimpse of all these different eras. (Annoyingly you can’t really get non-English trailers this way.)
TV series are essentially the same, but just different enough (films have “titles”, series have “names”) that I ended up duplicating all the code rather than adding switches for the different behaviour throughout.
Board games
BoardGameGeek is the most comprehensive source of information about board games, but its data is deceptively poor. Issues include: Structured information stored as formatted text within descriptions; poorly defined category tags; very few and sporadically applied setting tags; double-encoded HTML entities. The “new” API (still in Beta) is XML based and heavily rate-limited. There are no comprehensive data dumps, so the only approach is the excruciatingly slow task of downloading all 160,000 records over several days.
My scripts then scrape the descriptions looking for eras and places. The biggest challenge here is distinguishing descriptions of the history of the game (“…a gambling game, first mentioned in Chinese texts in the late 18th century,”) or its manufacture (“First published in Dresden in 1967”) from descriptions of the setting of the game (“The year is 1626, and France is under the control of Cardinal Richelieu”). I experimented with natural language processing libraries (too inaccurate) and LLMs (too slow) before falling back to a lot of regular expression matching, but may revisit this.
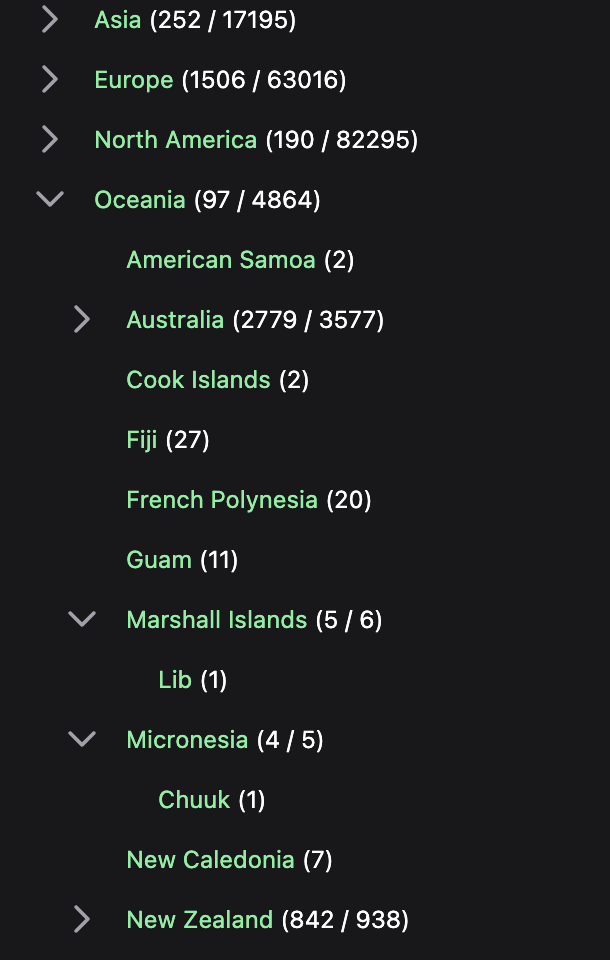
I made the early decision to treat places as points, rather than geographic boundaries. This simplifies geographic data enormously, and avoids complicated issues like boundaries moving over time.
I’m using a combination of the high-quality, well-structured Geonames datasets with the somewhat dubious GADM which lacks any explanation of who maintains it or how, and has inexplicable holes in the data (such as the record for England missing a name). But GADM contains lat/longs, which Geonames doesn’t. It’s not ideal.
From these sources my scripts load countries, cities, admin1 boundaries (eg, California, England) and in some cases admin2 boundaries (eg, Oxfordshire). To these I have some hand-made datasets of continents, seas (eg Adriatic, Tasman, North Atlantic), landmarks (221B Baker St, Alcatraz), mountains (Denali, the Himalayas), regions I call “blocs” for want of a better word (eg Northern Europe, Southeast Asia).
It’s a pretty fun experience to drop a few dots on a map, named from my own general knowledge, run some scripts, and find a bunch of movies and books suddenly emerge out of the woodwork. But it means gaps in my knowledge translate into gaps in the data, which is why I prefer using actual datasets where possible.
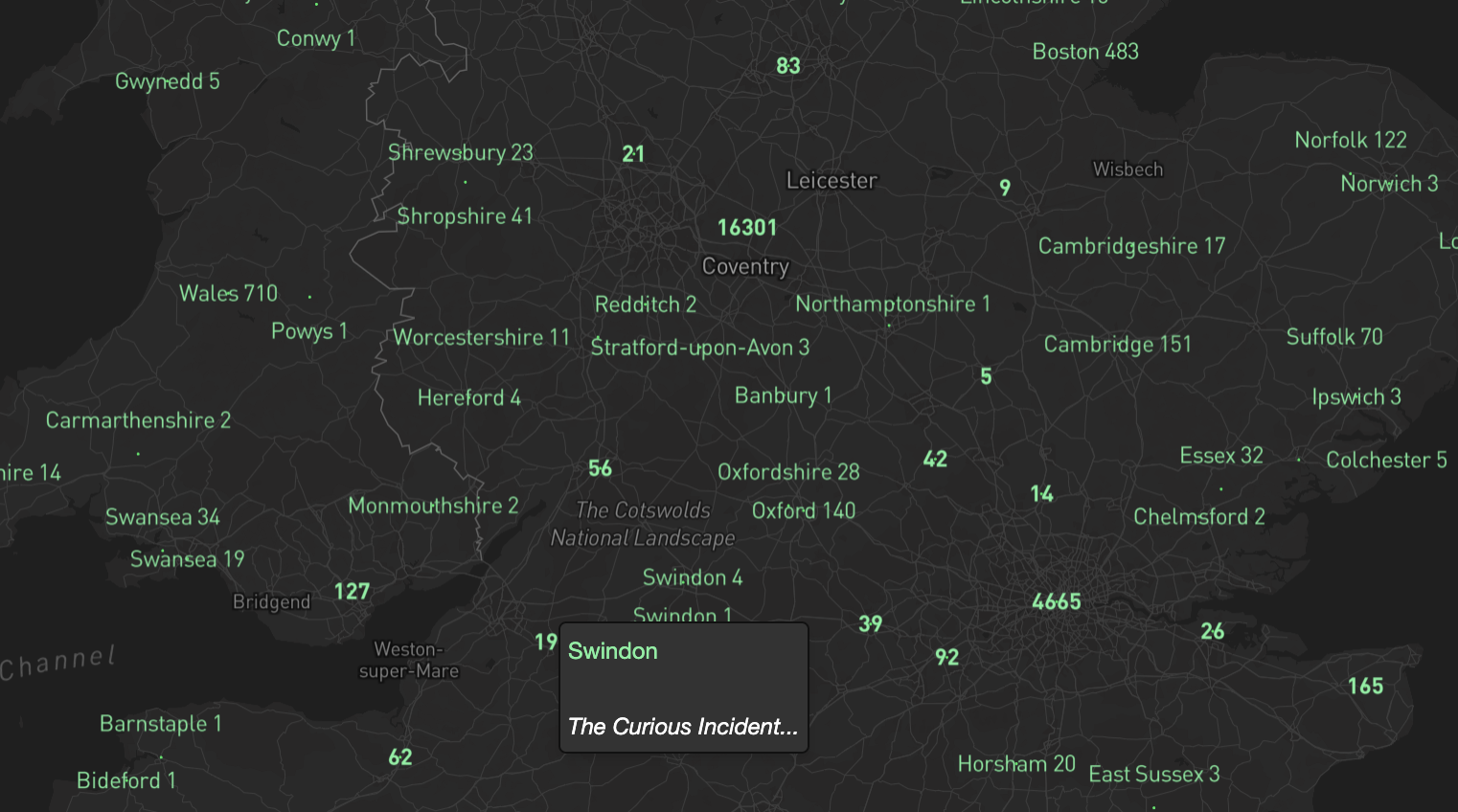
The Curious Incident of the Dog in the Night-time is definitely the only thing I have read or watched set in Swindon.
There is also a lot of post-processing to remove problematic place names (Pool is a region in the Republic of the Congo, but probably not what people intended) and to add additional synonyms like DC, Saigon and Aeotearoa.
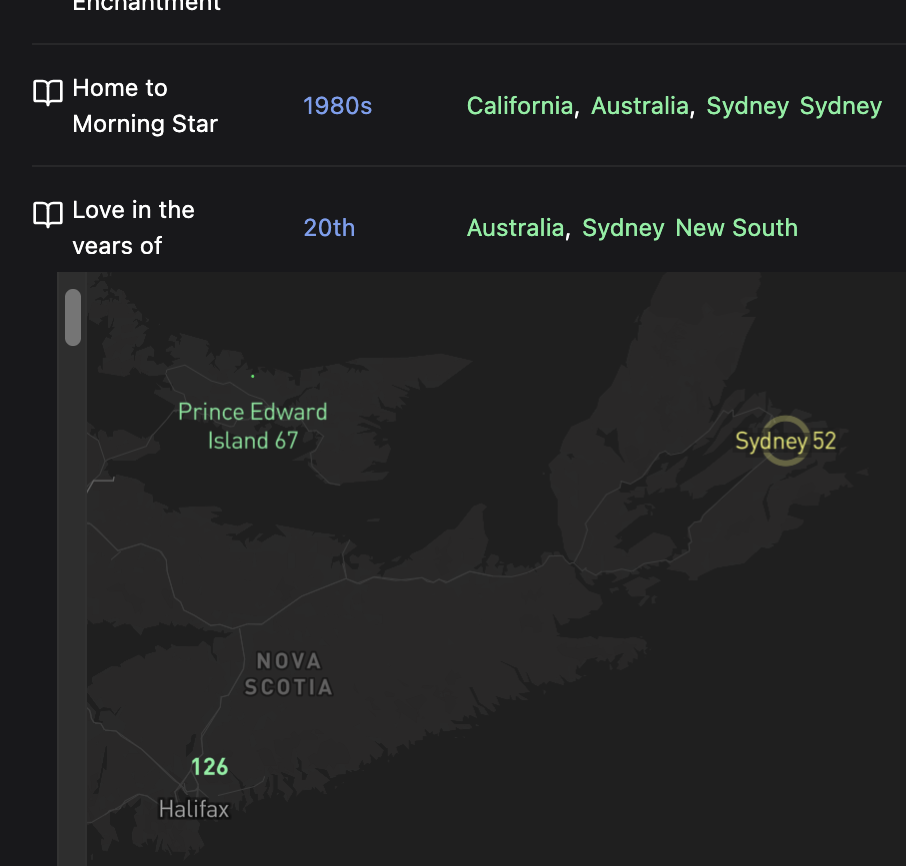
Sydney, Nova Scotia. I should probably be thankful there aren’t more ambiguous place names like this.
Eras
I have not yet come across any useful machine-readable set of eras (Wikidata is perhaps one to try, but there’s one more learning curve). The main dataset of eras is derived from Wikipedia’s List of time periods, which I used ChatGPT to convert into CSV format.
It is supplemented with time periods found in OpenLibrary. It’s pretty easy to use any “subject:time” tag that contains year-like numbers, such as Bombardment, 1943-1944. In this way, if an OpenLibrary user tags a book with a named era, it will then match films, series and board games in those respective databases.
Back end
I wrote the backend in Node/Typescript/Bun/ZX/Hono. The data processing takes place using DuckDB, but the data is then exported into a Postgres server for querying. DuckDB can be used as a production back-end, but in practice it is easier to come across cheap/free Postgres hosting than a server with enough memory to host a database of this size. I think.
Front end
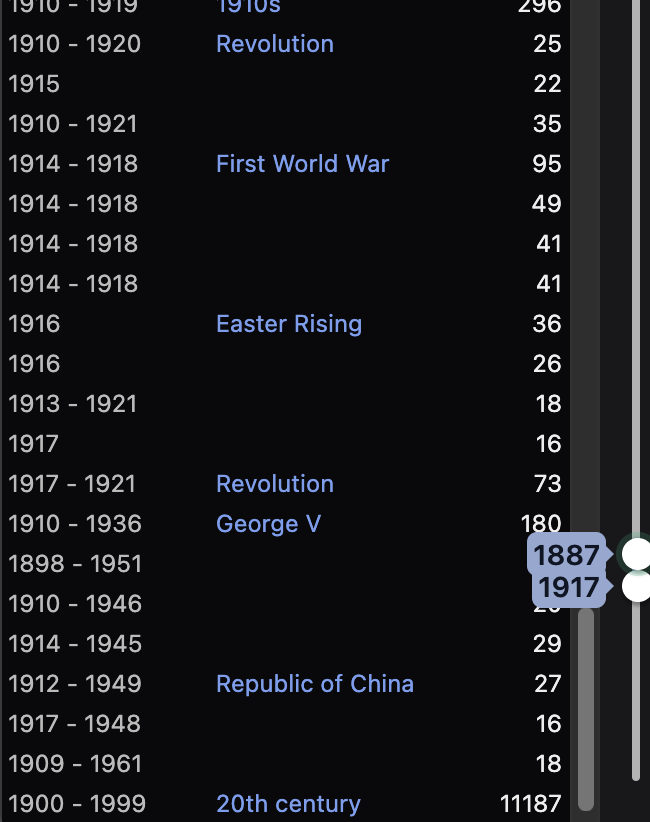
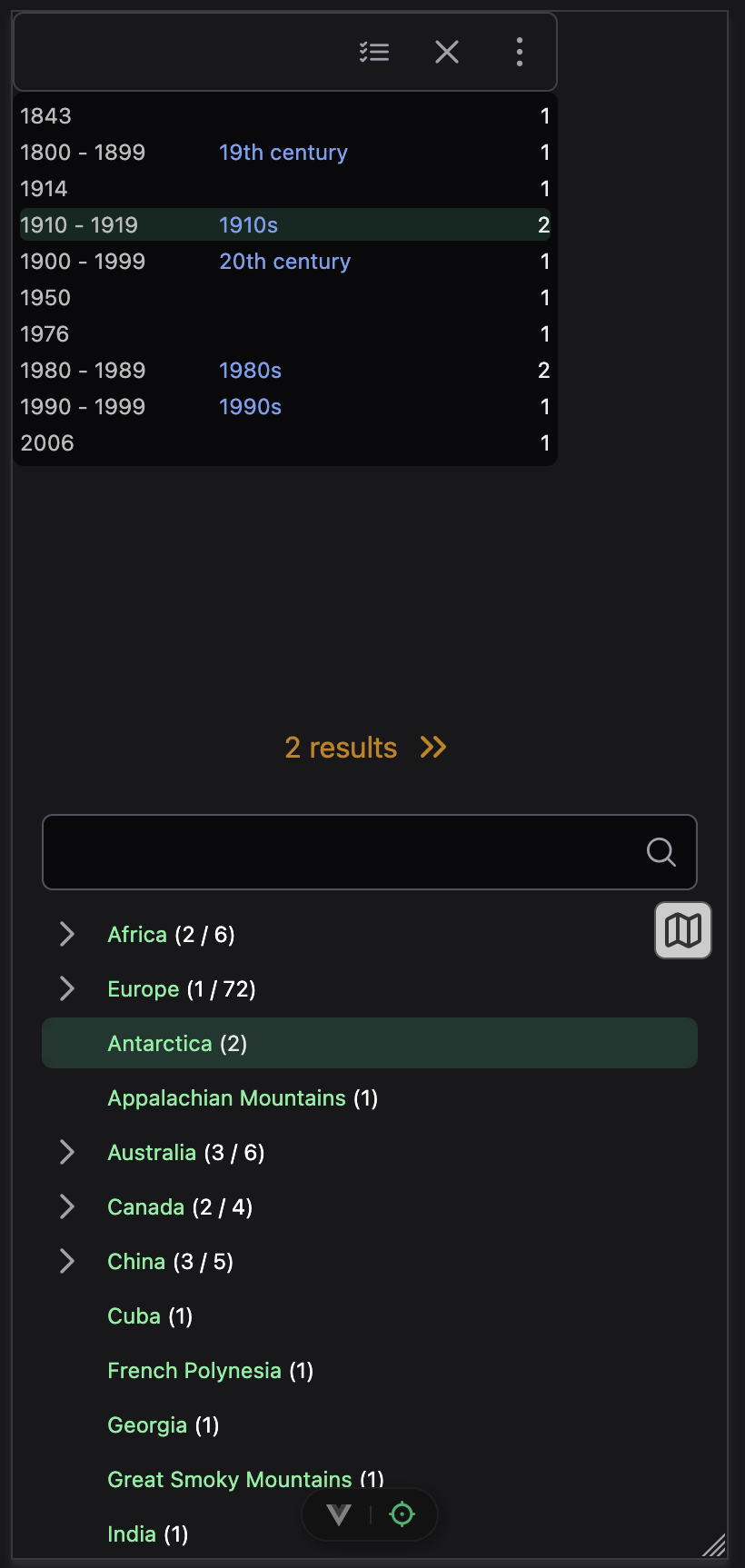
The front end is a pretty conventional Vue app, with Primevue components and Tailwind CSS. Designing and building the interface has been particularly challenging, with so few references to draw upon. What’s the best way to let the user pick a period of history? Does “1830s” also mean books tagged 1837? Does it include books tagged 19th century? What about 1835-1857? Does the user have opinions on these questions? How do they indicate such?
Cramming such a big and complex interface onto mobile is inherently difficult. Currently there are 5 main panels: eras list, places list, places map, items list, item detail.
My approach so far is: start with eras list (top), places map (bottom). There’s a toggle to switch the map for the places list. When you select an era or place, provide a prompt to see the items list, which slides out as a drawer. Tap an item, and half that drawer becomes the detail page.
More questions!
There’s a lot more work to do. One interesting question is how to manage eras that are geographically bounded: “US Civil War” is a period of time, but it also tells you the thing happened in the US. “Tang Dynasty” probably means the thing was set in China, as well as being from 623 to 907 AD.
Ultimately I would love to support really fine-grained time and place annotations: pages 87 to 116 and 180 to 231 of the book are set in this neighbourhood of Edinburgh in 1843.
If there is interest, I may enable crowd-sourced features. But maybe editorial energy would be better spent editing directly on themoviedb.org or openlibrary.org for instance.
Other kinds of things could be incorporated, such as video games (Video Game Geek perhaps) and theatre plays. Theatre productions can be set in different times and places from their original script, too.
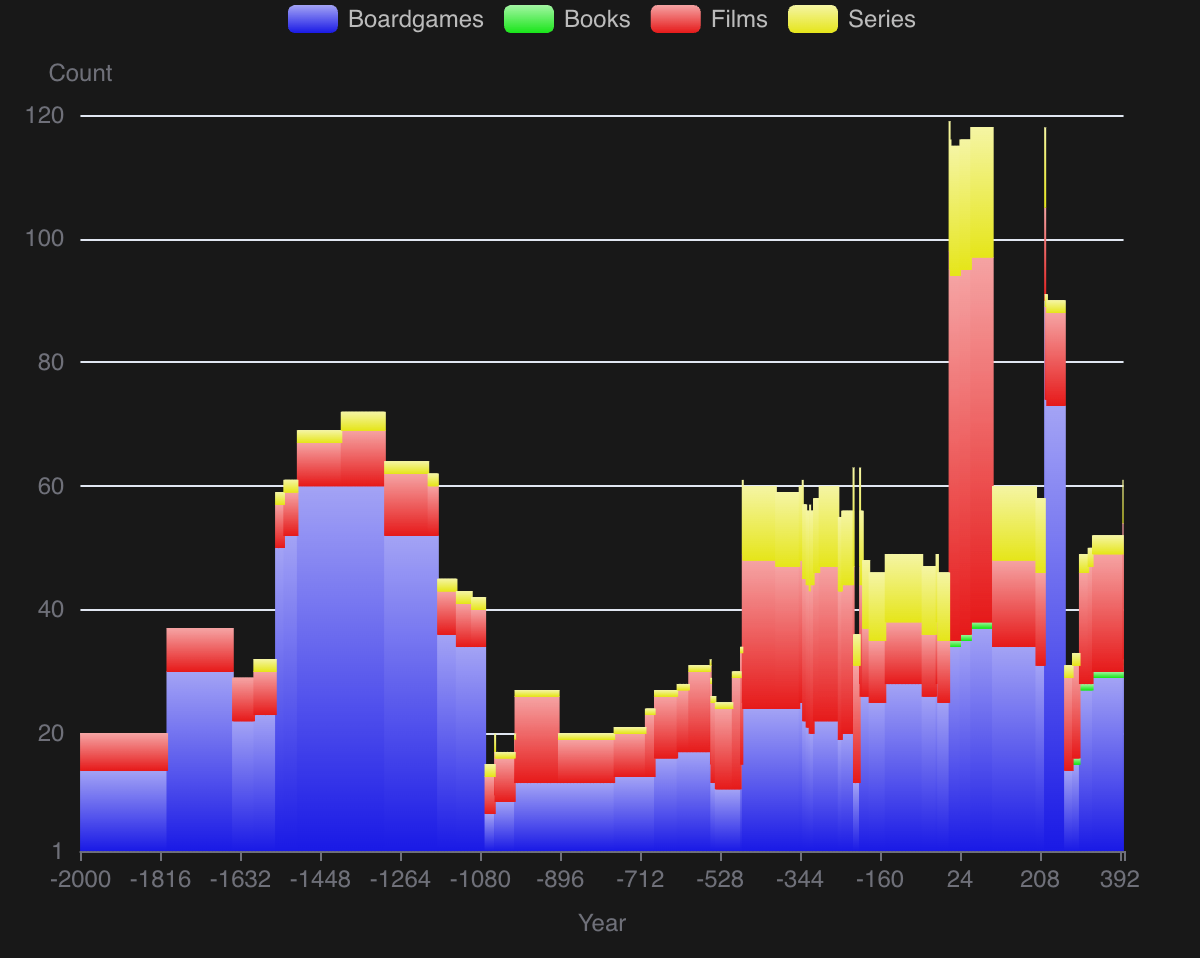
There’s a lot of possible data visualisations to make as well, like this fun chart of content set in times BC.

Recent Comments