
Reflecting on Salt. (Credit: Psyberartist, CC-BY 2.0)
Salt, or SaltStack, is an automatic deployment tool for clusters of machines, in the same category as Chef, Puppet and Ansible. I’ve previously used Chef, found the experience frustrating, and thought I’d give Salt a go. The task: converting my tilemill-server bash scripts, which set up a complete TileMill server stack, with OpenStreetMap data, Nginx and a couple of other goodies.
The goals in this kind of automation for me are threefold:
- So I can quickly build new servers for Mapmaking for Academics workshops.
- So I can manage other, similar (but slightly different) servers, such as cycletour.org and gis.researchmaps.net. “Manage” here means documenting and controlling the slight configuration differences, being able to roll out further changes (such as web passwords) without having to log in.
- So other people can do this too. (That is, the solution has to be simple enough to explain that other people can do it).
The product of my labours: https://github.com/stevage/saltymill
Disclaimers and apologies
A week is too soon to feel the real benefits of automatic deployment and configuration management, but plenty long enough for frustrations and annoyances. There are lots of good things about Salt, but those will go in another post.
I’ve intentionally written this post as I go, to document things that are surprising, counter-intuitive or bothersome to the newcomer. Once you become familiar with a system, it’s much harder to remember what it was like as a newbie, and easier to make allowances for it. So experienced Salt users will probably rankle at the wilful ignorance displayed herein.
A few things I quickly appreciated, compared to Chef:
- Two parties, not three. Chef has the client (your laptop), the Chef Server (which I never used because it was too complicated) and the target machine itself. Salt doesn’t have the client, so you do everything either on the master (“salt ‘*’ state.highstate) or on the target machine in masterless mode (“salt-call –local state.highstate)
- No need for “knife upload”: the Salt Master just looks for your files in /srv/salt, so you can use any method you like for getting them there. I always hated having to upload recipes, environments etc individually – you always forgot something.
- YAML rather than Ruby.
- A nifty command line tool that lets you try states out on the fly, or run commands remotely on several servers at once. (Chef’s shell, formerly ‘shef’, never really worked out for me.)
Mediocre documentation
Automatic deployment systems are complicated, and you’d love some clear mental concepts to hang on to. Unfortunately, Salt’s chosen metaphor is pretty clumsy (salt grains, pillars, mines…meh), and they’re not well explained. Apparently the concept of a “state” is pretty important to Salt, but even after reading much documentation and quite a reasonable amount of hacking away, I still have only the vaguest notion of what a Salt state is. What’s a “high state”? A “low state”? How can I query the “state” of a minion? No idea. It’s hard to tell if “states” are an implementation magic that makes the whole thing work, or if I, the user am supposed to know about them.
(After more digging around, I think “state” has several meanings, of which one is just one of the actions defined in a SLS file.)
And then, strangely, how do you refer to the most important objects that you work with, the actual code that specifies what you want done? “SLS files”. Or “state files”. Or “SLS[es]”. Or “Salt States”. Or “Salt state files”. Those terms are all used in the docs. (I thought they were also called “formulas“, but those are apparently only pre-canned state files.)
YAML headaches
It turns out YAML has some weird indenting and formatting rules that occasionally ruin your day. Initially it’s especially tedious having to learn this extra language and its subtleties (> vs |, multi-line hyphenated lists versus single line square-bracketed lists) when you just want to get started – it steepens the learning curve.
IDs, names
The behaviour of statement IDs is cute at first, but not well explained, and becomes pretty tiresome. The idea is you can write this:
httpd:
pkg.installed
Succinct, huh? That’s actually shorthand for this:
install_apache_please:
pkg:
- name: httpd
- installed
That is, the “id” (httpd) is also the default value for “name”. Secondly, you can compress one item of the following list (“installed”) onto the function name (“pkg”) with a dot.
So far, so good. But it quickly leads to this kind of silliness:
"{{ pillar.installdir}}/myfile.txt":
file.managed:
- unless: ...
another_command:
cmd.wait:
- watch: [ "{{ pillar.installdir}}/myfile.txt" ]
Free-text strings don’t make great IDs. On the whole, I’d prefer a syntax which is robustly readable and predictable, rather than one which is very succinct in special cases, but mostly less so.
The next problem is that all those IDs have to be unique across all your .sls files. That’s tedious when you have repetitious little actions that you can’t be bothered naming properly.
Another annoyance is that Salt’s data structure sometimes requires lists, and sometimes requires dicts, and it’s hard to remember which is which. For example:
finishlog:
cmd.run:
- name: |
echo "All done! Enjoy your new server.<br/>" >> /var/log/salt/buildlog.html
file.managed:
- name: /var/log/salt/index.html
- source: salt://initindex.html
- template: jinja
- context:
buildtitle: "Your server is ready!"
buildsubtitle: "Get in there and make something."
buildtitlecolor: "hsl(130,70%,70%)"
Notice how the first level of indentation doesn’t have hyphens, the second level does, then the third level doesn’t? I’m not sure what the philosophy is here – it looks to me like each level is just a list of key/value pairs.
Jinja templating logic
Jinja is a fantastic templating language. But Salt uses this template language as its core programming logic. That’s like writing a C program using macros all over the place. It’s sort of ok as a way to access data values:
update_data:
cmd.run:
- cwd: {{ pillar['tm_dir'] }}
Here, the {{ … }} bit is a Jinja substitution, so the actual YAML code that gets parsed and executed looks like this:
update_data:
cmd.run:
- cwd: /mnt/saltymill
As most people who have dealt with macro preprocessors know, they rapidly get complex and very hard to debug. The error you see is a YAML parse error, but is the problem in your YAML code, or in what got substituted by Jinja?
It’s certainly possible to use the full range of Jinja functions (that is, {% … %} territory) inside Salt formulas, but for sanity I’m trying to avoid it. On the flip side, certain things that I expected to be easy, like defining a variable in a state {% set foo = blah %} and then being able to access it from inside any other template, turn out to not work. You need to explicitly pass context variables around, or import state files, and it becomes quite cumbersome.
Help may be at hand. Evan Borgstrom also noticed that “simple readability of YAML starts to get lost in the noise of the Jinja syntax” and is working on a new, pure Python syntax called NaCl.
Many ordering options
There are about 4 competing systems simultaneously operating to determine which order actions get executed in, ranked here from most important to least important.
- Requisite order: The “preferred”, declarative system, where if X requires Y and Z requires X, then Salt just figures out that Y has to happen first.
- Explicit order: you can set an “order flag” on an action, like “order: 1” or “order: last”. Basically, if you’re tearing your hair out with desperation, I think. (I tried it once, and it seemed to have no effect.)
- Definition order: things happen in the order they’re declared in. (By far my preferred option). This doesn’t always seem to work, in the top.sls, for reasons I don’t understand.
- Lexicographical order (yes, really): actions are executed in alphabetical order of their state name. (Apparently this was a good thing because at least it was consistent across platforms.)
The requisite ordering system sounds good, but in practice it has two shortcomings:
- Repetitiveness: let’s say you have psql 10 commands that all strictly depend on Postgresql being installed. It’s very repetitive to state that dependency explicitly, and much more efficient to simply install Postgresql at the top of the formula, and assume its existence thereafter.
- Scope: Requiring actions in other files seems to prevent the running of just this file. That is, if in load_db.sls you do “require: [ cmd: install_postgres ]”, then this command line no longer works: salt ‘*’ state.sls load_db
I’m yet to see any advantages to a declarative style. I like the certainty of knowing that a given sequence of steps works. The declarative model implies that one day the steps might be rearranged based only on my statement of what the dependencies are.
Arbitrary rules
There’s a rule that says you can’t have the same kind of state multiple times in a statement. This is invalid:
/var/log/salt/buildlog.html:
file.managed:
- source: salt://initlog.html
file.append:
- text: Commencing build...
Why? I don’t know. The rules dictate that you have to do this:
/var/log/salt/buildlog.html:
file.managed:
- source: salt://initlog.html
append_to_that_file:
file.append:
- name: /var/log/salt/buildlog.html
- text: Commencing build...
Notice the cascade of consequences as this fragile “readability” tower crashes down:
- You can’t have two states of the same type in a statement, so we move the second state to a new statement; but:
- You can’t have two statements with the same ID, so we give the second statement a new ID; meaning:
- We now have to explicitly define the “name” of the file.append function.
Clumsy bootstrapping
I miss Chef’s elegant “knife bootstrap” though. In one command line command, Chef:
- Defines properties about the node, like its environment and role.
- Connects to the node
- Installs Chef
- Registers the node with the Chef server, or your client, or both.
- Starts a deployment, as required.
With Salt, these all seem to be manual steps:
- I SSH to the node
- I download and install Salt (using one-liner bootstrap script)
- I write ‘grains’ to the newly created /etc/salt/grains file (yes, I think I’m doing this wrong – roles should be defined through pillars maybe)
- The node then attempts to register itself with the Salt Master, but because the connection is insecure:
- I have to go to the Salt Master and accept the pending key: yes | salt-key -A [and the docs suggest you’re supposed to manually verify the keys!]
- Now I can launch a deployment: salt-master <nodename> state.highstate
When I rebuild a server, the above are preceded by these steps:
- Log in to OpenStack Dashboard, click ‘rebuild’ on the instance.
- Edit my ~/.ssh/known_hosts to remove the old SSH key.
- On the Salt Master, delete the old key: yes | salt-key <node> -d
There are probably ways of streamlining this process. I hope so, anyway, because it’s pretty clumsy. I don’t know yet whether the SaltMaster can automatically launch deployments when new nodes register.







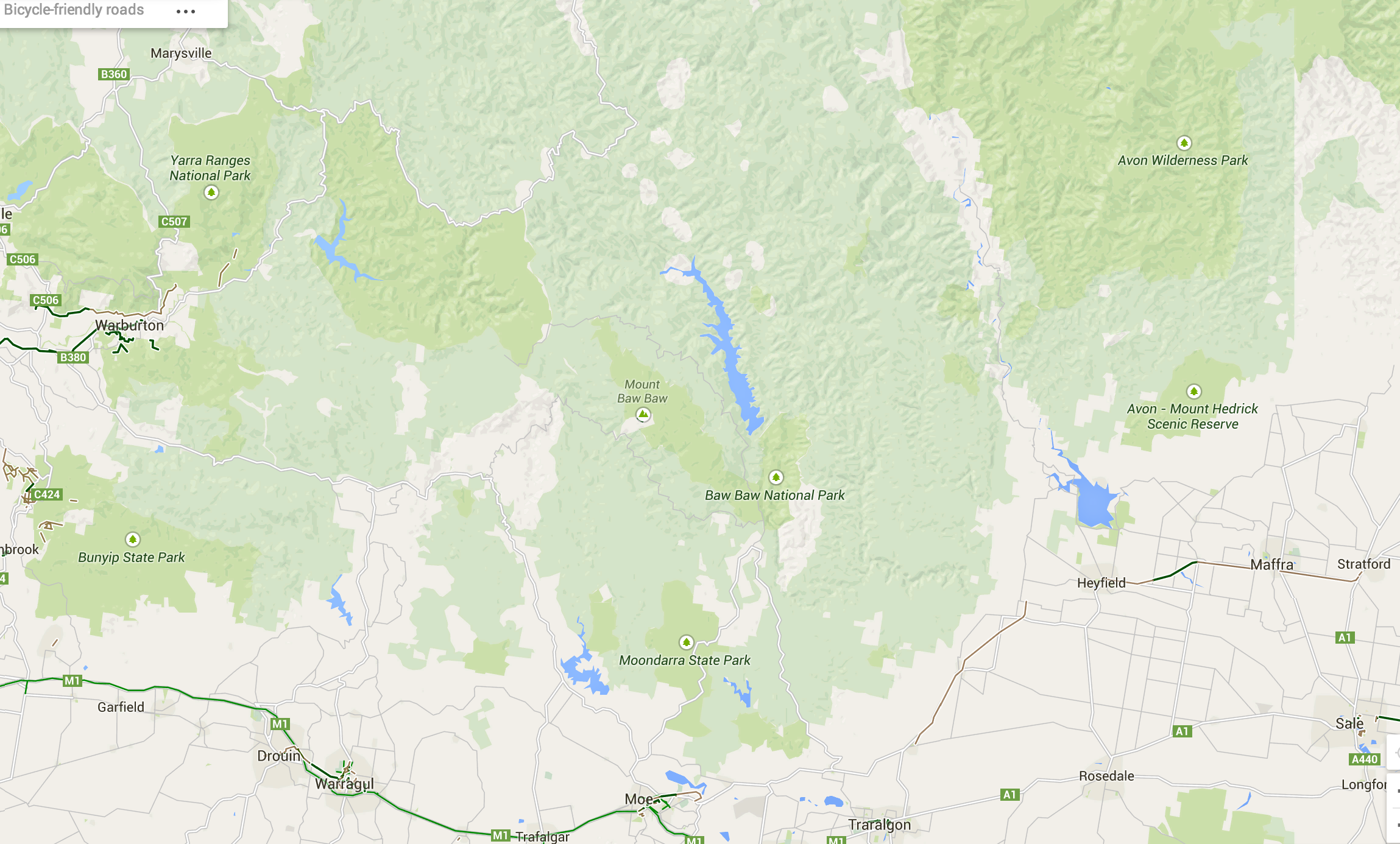
 The terrain data is a 20 metre-resolution digital elevation model from DEPI, within Victoria,
The terrain data is a 20 metre-resolution digital elevation model from DEPI, within Victoria, 





Recent Comments